Python에서 아름다운 수프와 셀레늄을 사용하여 크롤링하는 방법
먼저 크롤링이란 무엇입니까?
컴퓨터 소프트웨어 기술 웹사이트에서 필요한 정보 추출~을 위한 것이다
이 사이트는 또한 코드로 구축되어 있으므로 어느 정도 표준화되어 있습니다. 웹 크롤러는 이러한 규칙에 따라 필요한 정보만 추출합니다.
뉴스 기사 웹 페이지에서 기사 제목이나 콘텐츠를 수집하거나 소셜 미디어에서 게시물 콘텐츠와 좋아요를 수집하는 것을 크롤링이라고 합니다.
파이썬으로 할건데 가장 대표적인 라이브러리는 아름다운 수프수업 셀렌예.
이 두 라이브러리를 파헤치기 전에 네트워크가 어떻게 구축되는지 살펴보겠습니다.
다음은 자주 방문하는 네이버 페이지입니다.
아무 곳이나 마우스 오른쪽 버튼 클릭 -> 검사(또는 페이지 소스 보기)를 클릭하여 웹 페이지의 구조를 확인합니다.


이렇게 웹 페이지 구조가 HTML 형식이 되고, 오른쪽 클릭 -> 페이지 소스 검사 또는 보기를 통해 코드 소스를 볼 수 있습니다.
아래 그림과 같이 인스펙션 창에서 특정 코드 위에 마우스를 올리면 해당 코드로 웹 페이지의 어느 부분이 강조 표시되는지 확인할 수 있습니다.
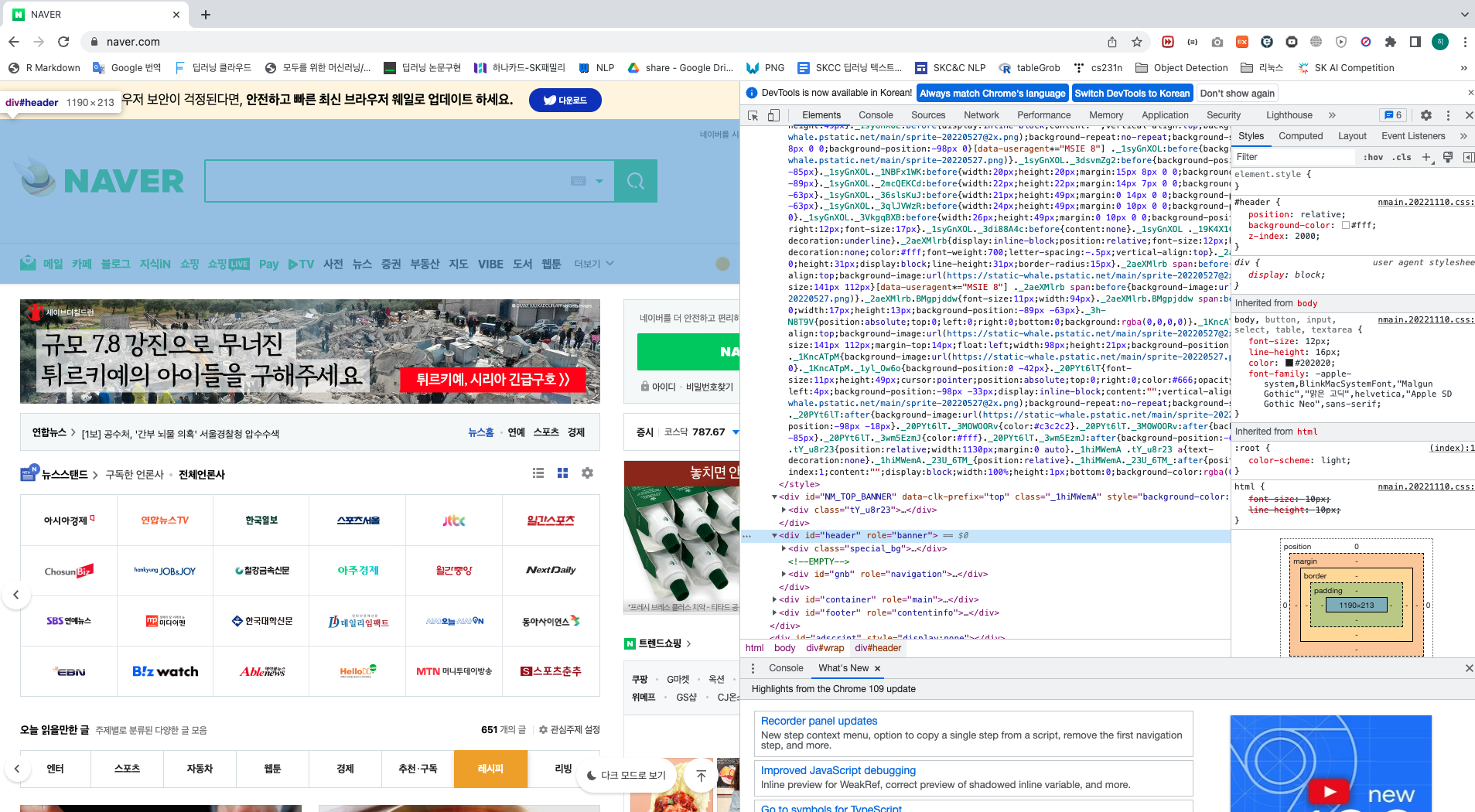
이와 같이 소스에 따라 웹 페이지에서 원하는 정보를 얻을 수 있습니다.
이 출처 상표그것은에 의해 호출됩니다
여기서 태그란 웹 페이지의 대상 부분에 글자 크기, 글자 색, 글자 모양 등을 변경하거나 링크를 걸거나 이미지를 표시하는 등의 일종의 마크업을 의미한다.
예제 태그는 다음과 같습니다.
안녕하세요
원래 <标签名称> … 형태로 구성
예를 들어 네이버에서 “평방미터당 3211만 원에 집을 팔고 싶은 안양 재건축 회원”이라는 제목의 기사 제목은 다음과 같은 HTML 태그로 표현된다.
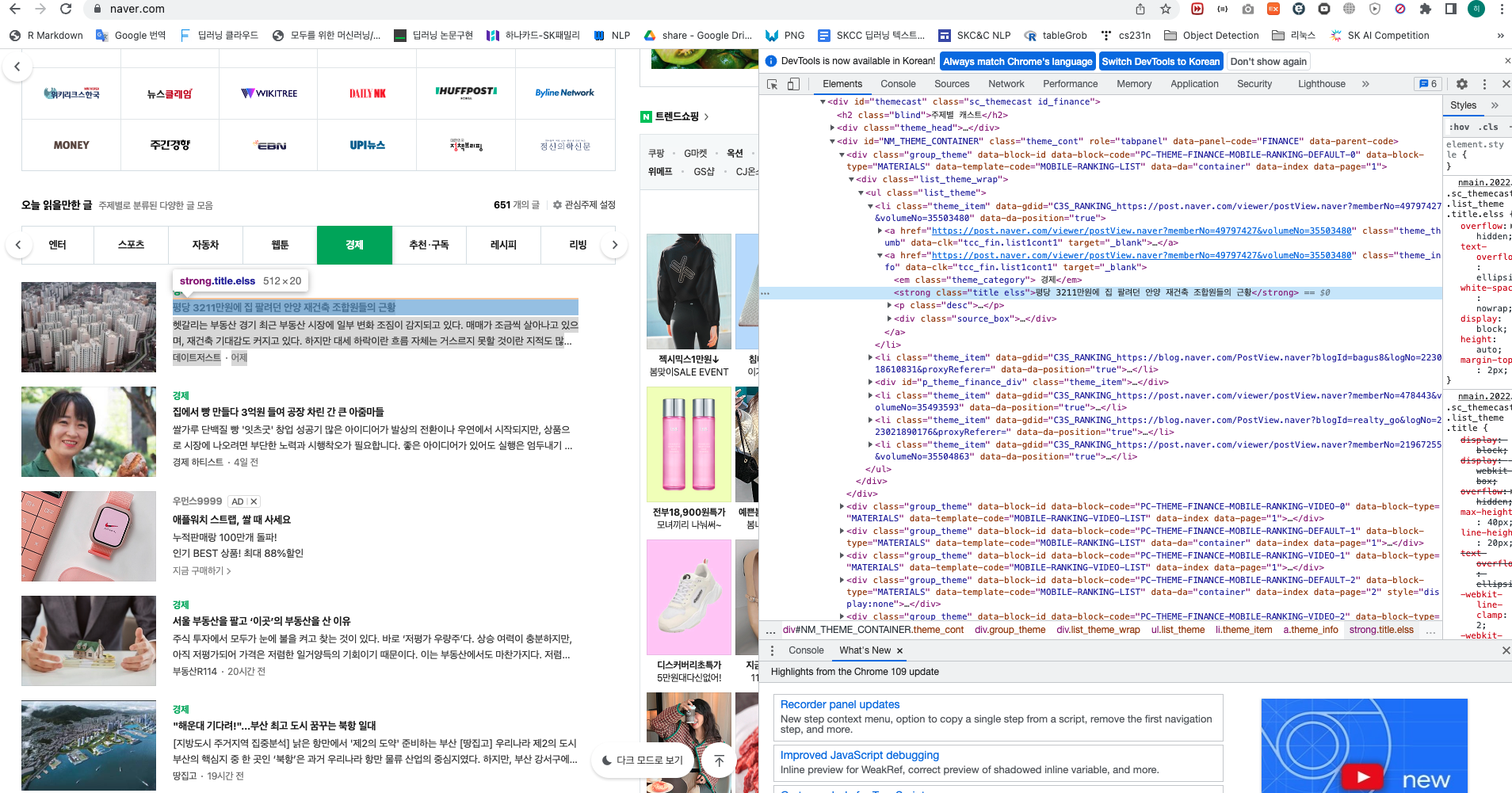
자세히 살펴보다, 레이블
tag_name의 예로는 p, div 및 strong이 있고 속성의 예로는 id 및 class가 있습니다.
(참고로 div는 문단을 나타내는 태그, p는 인라인 태그를 나타냅니다. 각각의 의미를 알면 좋겠지만 모르더라도 스크랩할 수 있으니 자세한 설명은 따로 찾아보세요. )
파이썬에서 스크래핑을 위한 대표적인 라이브러리는 아름다운 수프수업 셀렌예.
두 라이브러리의 차이점은 BeautifulSoup은 위 웹페이지의 소스코드 중 필요한 부분만을 파싱하기 위한 라이브러리이고, Selenium은 자동으로 웹사이트를 제어하기 위한 라이브러리입니다.예.
참고로 요청 라이브러리는 웹 페이지 소스를 로드하는 데 사용됩니다.
위의 네이버 페이지를 예로 들면 BeautifulSoup은 웹 페이지의 소스를 요청한 다음 뉴스 가판대에 있는 뉴스 기사 또는 오늘 읽을 가치가 있는 메뉴를 추출하는 데 사용됩니다.
한편, 오늘 읽어볼만한 글에서는 Selenium이 캐리지 리턴 메뉴를 “딸깍 하는 소리“해봐, 페이지를 아래로 넘겨”스크롤“어떤 키워드”입력하다“하다”입력하다“를 클릭하는 등 웹 사이트를 제어하는 데 사용됩니다.
BeautifulSoup은 웹 페이지 소스에만 적용됩니다. 상표찾는 것이 목적이다 찾다() 개체 및 선택하다() 사용자 대상
(아래는 실제 웹페이지를 활용하여 실습한 부분입니다.)
찾다()나 하나를 선택() 개체는 찾은 첫 번째 태그를 반환합니다. 모두 찾기()또는 선택하다() 이 개체는 모든 해당 태그를 반환합니다.
예를 들어 다음과 같은 샘플 웹 페이지 소스 코드가 있다고 가정합니다.

필요한 라이브러리를 로드하고 위의 소스를 BeautifulSoup 개체로 반환합니다.
|
하나
2
|
수입 필요하다 # 페이지 소스 가져오기
~에서 BS4 수입 아름다운 수프 ~처럼 무의미한 말 # 받은 페이지 소스를 파싱
|
씨에스 |
“p” 태그에 대한 정보를 추출하려면 다음을 수행할 수 있습니다.
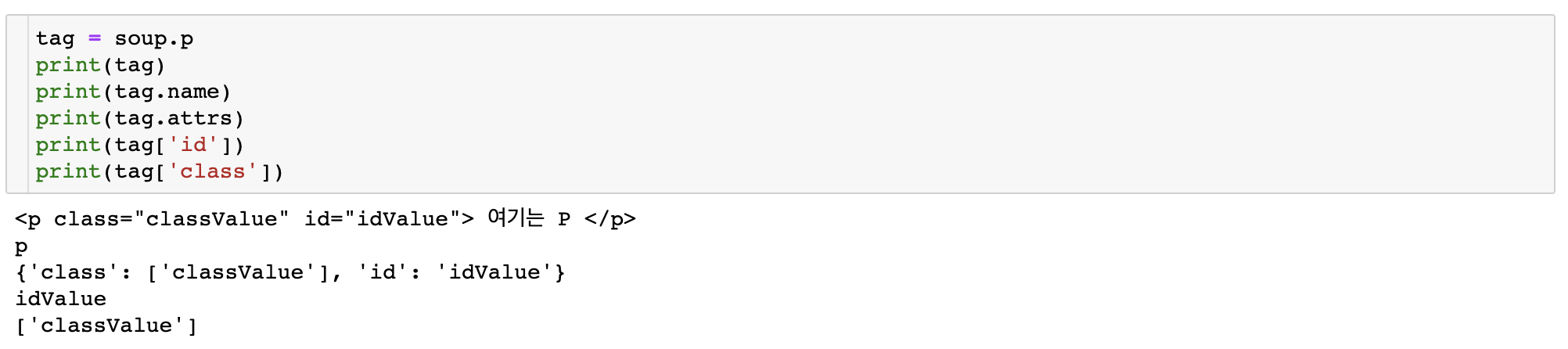
수프.p“p” 태그에 대한 정보를 입력하고,
태그 이름레이블 이름으로,
라벨 속성속성으로,
태그(‘아이디’)id 속성에 해당하는 값으로,
레이블(‘클래스’)를 사용하여 클래스 속성에 해당하는 값을 추출할 수 있습니다.
“div” 태그도 마찬가지입니다.

지금 찾다() 태그 이름으로 태그를 추출하는 방법은 다음과 같습니다.

또는 속성과 값으로 추출하는 방법입니다.

위의 예에서 찾다()그리고 모두 찾기()차이점도 볼 수 있습니다.
다음 선택하다()탭을 빼는 방법이기도 합니다.
태그 이름을 기준으로 아래와 같이 찾을 수 있습니다.

속성에서 다음과 같이 클래스에 “.”을 사용하고 id에 “#”을 사용합니다.

태그 이름과 클래스 또는 ID를 사용하여 다음을 수행할 수 있습니다.

찾다()그리고 선택하다()태그를 지정하는 방법은 비슷하지만 특정 경로의 태그를 반환할 때 find는 코드를 반복해야 하고 select는 하위 경로를 직접 지정할 수 있습니다.
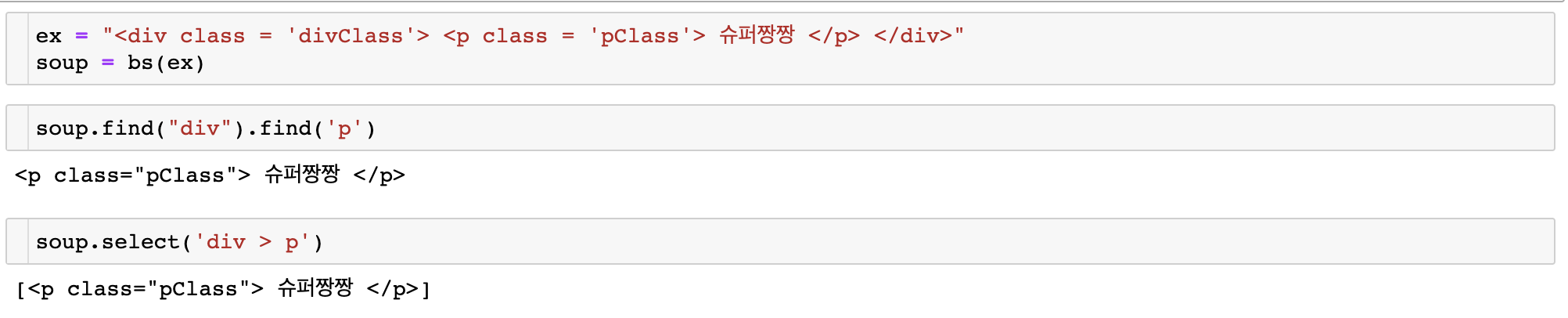
또한 select가 더 빨리 실행되고 메모리를 적게 사용하므로 find보다 select를 사용하는 것이 좋습니다.
실제 웹 페이지를 심각하게 크롤링하는 관행은 다음 기사에서 계속됩니다.