(DB/SQL) SQL로 데이터 처리 (4).Subquery, NULL
이 게시물 고급 백엔드 개발자의 데이터베이스 및 SQL 소개제가 받아서 정리한 글입니다.
쿼리 내의 쿼리
– 하위 쿼리
// if ID가 14인 임직원보다 생일이 빠른 임직원의 ID, 이름, 생일을 알고 싶다.
SELECT brith_date FROM employee WHERE id = 14; // 14인 임직원의 생일 확인 == 1992-08-04
SELECT id, name, birth_date FROM employee WHERE birth_date < '1992-08-04';
// 위 두개의 query를 아래로 합침
SELECT id, name, birth_date FROM employee // outer query
WHERE birth_date<(
SELECT birth_date FROM employee WHERE id = 14 // subquery
);
하위 쿼리(중첩 쿼리 또는 내부 쿼리): SELECT, INSERT, UPDATE, DELETE에 포함된 쿼리
외부 쿼리(메인 쿼리): 하위 쿼리를 포함하는 쿼리
하위 쿼리는 ( )에 설명되어 있습니다.
하위 쿼리는 하나 이상의 속성을 비교할 수 있습니다.
// if ID가 5인 임직원과 같은 프로젝트에 참여한 임직원들의 ID를 알고 싶다.
SELECT proj_id FROM works_on WHERE empl_id = 5 // proj_id == 2001, 2002
SELECT DISTINCT empl_id FROM works_on
WHERE empl_id != 5 AND (proj_id = 2001 OR proj_id = 2002)
// DISTINCT를 사용한 이유는 2001, 2002에 둘다 참여한 임직원이 있을 수 있기 때문.
// proj_id = 2001 OR proj_id = 2002 => proj_id IN (2001,2002) 로 변경 가능
// 위 예제를 아래처럼 바꿀 수 있음
SELECT DISTINCT empl_id FROM works_on
WHERE empl_id != 5 AND proj_id IN(
SELECT proj_id FROM works_on WHERE empl_id=5
);
-v 입력(…)
v IN(v1, v2, v3): v가 (v1, v2, v3,…) 중 하나와 같으면 TRUE를 리턴합니다.
여기서 (v1, v2, v3, …)는 명시적인 값의 집합이거나 하위 쿼리의 결과(집합 또는 다중 집합)일 수 있습니다.
v NOT IN (v1, v2, v3) : v가 (v1, v2, v3,…)의 모든 값과 다른 경우 TRUE를 반환합니다.
– 규정되지 않은 속성
속해 있는 테이블을 지정하지 않는 속성이 있는 테이블
속성을 사용하는 쿼리를 포함하여 쿼리 외부에 존재하는 모든 쿼리에서
해당 속성 이름으로 가장 가까운 테이블을 참조합니다.
// ID가 5인 임직원과 같은 프로젝트에 참여한 임직원들의 ID와 이름을 알고 싶다.
SELECT id, name
FROM employee
WHERE id IN (
SELECT DISTINCT empl_id
FROM works_on
WHERE empl_id != 5 AND proj_id IN(
SELECT proj_id
FROM works_on
WHERE empl_id=5
)
);
// 서브 쿼리를 FROM 위치로 가게 하기
SELECT id, name
FROM employee
(
SELECT DISTINCT empl_id
FROM works_on
WHERE empl_id != 5 AND proj_id IN(
SELECT proj_id
FROM works_on
WHERE empl_id=5
)
)AS DSTNCT_E // AS로 별칭을 붙임
WHERE id = DSTNCT_E.empl_id;
상관 쿼리: 하위 쿼리가 외부 쿼리의 속성을 참조하는 경우 이를 상관 하위 쿼리라고 합니다.
-존재하다
하위 쿼리의 결과가 하나 이상의 행이면 TRUE를 반환합니다.
NOT EXISTS의 경우 행이 하나도 없으면 TRUE를 반환합니다.
IN과 EXISTS는 대부분 같은 의미로 사용됩니다.
// ID가 7 혹은 12인 임직원이 참여한 프로젝트의 ID와 이름을 알고 싶다
SELECT P.id, P.name
FROM project P
WHERE EXISTS(
SELECT *
FROM works_on W
WHERE W.proj_id = P.id AND W.empl_id IN(7,12)
);
// 아래로 변경 가능
SELECT P.id, P.name
FROM project P
WHERE id IN(
SELECT W.proj_id
FROM works_on W
WHERE W.empl_id IN(7,12)
);
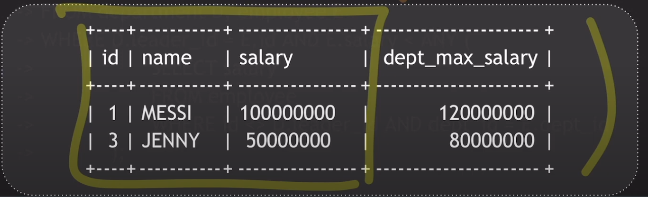
// 리더보다 높은 연봉을 받는 부서원을 가진 리더의 ID와 이름, 연봉과 해당 부서의 최고 연봉은?
SELECT E.id, E.name, E.salary,
(
SELECT max(salary)
FROM employee
WHERE dept_id = E.dept_id
) AS dept_max_salary
FROM department D, employee E
WHERE D.leader_id = E.id AND E.salary < ANY(
SELECT salary
FROM employee
WHERE id <> D.leader_id AND dept_id = E.dept_id
);
-어느
v comparison_operator ANY(subquery): 하나 이상의 하위 쿼리가 결과를 반환합니다.
v와의 비교가 TRUE이면 TRUE를 반환합니다.
어떤 사람들도 그렇습니다.
-모두
v comparison_operator ALL(하위 쿼리): 하위 쿼리에서 반환된 모든 결과
v와의 비교가 TRUE이면 TRUE를 반환합니다.
3값 논리
-유효하지 않은
NULL에는 세 가지 의미가 있습니다.
1. 알 수 없음: 이 사람에 대한 정보를 알 수 없습니다.
2. 사용할 수 없거나 보류됨: 해당 개인의 정보는 비공개이며 사용할 수 없습니다.
3. 해당사항 없음: 본인의 정보 자체를 알 수 없습니다. 게다가.
위와 같은 이유로 NULL을 비교할 때 동일하게 취급하기 어렵습니다.
어떤 것이 NULL과 같은지 확인하려면 is, not = 를 사용하십시오.
– 3값 논리
SQL은 비교/논리 연산의 결과로 TRUE, FALSE 및 UNKNOWN을 갖습니다.
UNKNOWN은 TRUE 또는 FALSE일 수 있음을 의미합니다.
SQL에서 NULL을 사용한 비교 작업의 결과는 UNKNOWN입니다.
NULL = NULL의 결과도 알 수 없습니다.
– WHERE 절의 조건
where 절의 조건이 TRUE로 평가되는 튜플만 선택합니다.
FALSE 또는 UNKNOWN이면 튜플이 선택되지 않습니다.
| v가 (v1, v2, 3)에 없음 == v != v1 AND v != v2 AND v != v3 | |
| 예를 들어 | 결과 |
| 3은 (1, 2, 4)에 속하지 않습니다. | 진짜 |
| 3은 (1, 2, 3)에 속하지 않습니다. | 잘못된 |
| 3은 (1, 3, NULL)에 속하지 않습니다. | 잘못된 |
| 3은 (1, 2, NULL)에 속하지 않습니다. | 알려지지 않은 |
SELECT D.id, D.name
FROM department AS D
WHERE D.id NOT IN(
SELECT E.dept_id
FROM employee E
WHERE E.brith_date >= '2000-01-01'
);
위의 예에서 한 사람이 NULL이면 정상적인 결과가 나오지 않을 수 있습니다. (NULL 출생 연도에 대해 2000이 존재할 수 있음)
이 문제를 해결하는 방법에는 3가지가 있습니다.
1. 처음부터 NOT NULL 제약 조건으로 항목을 설정합니다.
2. NULL이 반환되지 않도록 하위 쿼리에 IS NOT NULL을 설정합니다.
SELECT E.dept_id
FROM employee E
WHERE E.birth_date >= '2000-01-01'
AND E.dept_id IS NOT NULL3. NOT IN을 NOT EXISTS로 바꾸십시오.